使用
教程
视频教程合集:https://space.bilibili.com/3709626/lists/1422512
配置
WebUI 程序运行后会自动加载配置文件,可以通过 WebUI 程序进行配置修改(清空配置项可以看到配置项的说明),也可以手动修改配置运行。
配置都在 config.json(此处只列举了大部分,因为实在是太多了,懒了)
config.json
{
// 你的直播间号,兼容全平台,都是直播间页面的链接中最后的数字和字母。例如:123
"room_display_id": "你的直播间号",
// 选用的聊天类型:chatterbot/chatgpt/claude/chat_with_file/chatglm/sparkdesk/reread/none 其中reread就是复读机模式,none是不启用
"chat_type": "none",
// 弹幕语言筛选,none就是全部语言,en英文,jp日文,zh中文
"need_lang": "none",
// 请求chatgpt/claude时,携带的字符串头部,用于给每个对话追加固定限制
"before_prompt": "请简要回复:",
// 请求chatgpt/claude时,携带的字符串尾部
"after_prompt": "",
// 弹幕日志类型,用于记录弹幕触发时记录的内容,默认只记录回答,降低当用户使用弹幕日志显示在直播间时,因为用户的不良弹幕造成直播间被封禁问题
"comment_log_type": "回答",
"filter": {
// 弹幕过滤,必须携带的触发前缀字符串(任一)
"before_must_str": [],
// 弹幕过滤,必须携带的触发后缀字符串(任一)
"after_must_str": [
".",
"。",
"?",
"?"
],
// 本地违禁词数据路径(你如果不需要,可以清空文件内容)
"badwords_path": "data/badwords.txt",
// 最长阅读的英文单词数(空格分隔)
"max_len": 30,
// 最长阅读的字符数,双重过滤,避免溢出
"max_char_len": 50
},
// 答谢相关配置
"thanks": {
// 是否启用入场欢迎
"entrance_enable": true,
// 是否启用礼物答谢
"gift_enable": true,
// 入场欢迎文案
"entrance_copy": "欢迎 {username}",
// 礼物答谢文案
"gift_copy": "感谢 {username} 送的 {gift_name}",
// 最低礼物答谢金额
"lowest_price": 1.0
},
// Live2D皮
"live2d": {
// 是否启用
"enable": true,
// web服务监听端口
"port": 12345
},
"openai": {
"api": "https://api.openai.com/v1",
"api_key": [
"你的api key"
]
},
// claude相关配置
"claude": {
// claude相关配置
// 参考:https://github.com/bincooo/claude-api#readme
"slack_user_token": "",
"bot_user_id": ""
},
// chatglm相关配置
"chatglm": {
"api_ip_port": "http://127.0.0.1:8000",
"max_length": 2048,
"top_p": 0.7,
"temperature": 0.95
},
// 讯飞星火相关配置
"sparkdesk": {
// 两种类型 web api
"type": "web",
// web类型下 抓包中的cookie,详情见拓展教程
"cookie": "",
// web类型下 抓包中的fd
"fd": "",
// web类型下 抓包中的GtToken
"GtToken": "",
// api类型下 申请api后平台中的appid
"app_id": "",
// api类型下 申请api后平台中的appsecret
"api_secret": "",
// api类型下 申请api后平台中的appkey
"api_key": ""
},
"chat_with_file": {
// 本地向量数据库模式
"chat_mode": "claude",
// 本地文件地址
"data_path": "data/伊卡洛斯百度百科.zip",
// 切分数据块的标志
"separator": "\n",
// 向量数据库数据分块
"chunk_size": 100,
// 每个分块之间的重叠字数。字数越多,块与块之间的上下文联系更强,但不能超过chunk_size的大小。同时chunk_size和chunk_overlap越接近,构造向量数据库的耗时越长
"chunk_overlap": 50,
"chain_type": "stuff",
// 适用于openai模式,显示消耗的token数目
"show_token_cost": false,
"question_prompt": "请根据以上content信息进行归纳总结,并结合question的内容给出一个符合content和question语气、语调、背景的回答。不要出现'概括''综上''感谢'等字样,向朋友 直接 互相交流即可。如果发现不能content的信息与question不相符,抛弃content的提示,直接回答question即可。任何情况下都要简要地回答!",
// 最大查询数据库次数。限制次数有助于节省token
"local_max_query": 3,
// 默认本地向量数据库模型
"local_vector_embedding_model": "sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco"
},
// 语音合成类型选择 edge-tts/vits_fast/elevenlabs
"audio_synthesis_type": "edge-tts",
// vits_fast相关配置
"vits_fast": {
// 配置文件的路径
"vits_fast_config_path": "E:\\GitHub_pro\\VITS-fast-fine-tuning\\inference\\finetune_speaker.json",
// 推理服务运行的链接(需要完整的URL)
"vits_fast_api_ip_port": "http://127.0.0.1:7860",
// 选择的说话人,配置文件中的speaker中的其中一个
"character": "ikaros"
},
// so-vits-svc相关配置
"so_vits_svc": {
// 启用功能 true启用 false关闭
"enable": false,
// 模型配置文件路径
"config_path": "D:\\so-vits-svc\\configs\\ikaros_v1.json",
// 服务运行的ip端口(注意,请运行flask_api_full_song.py)
"api_ip_port": "http://127.0.0.1:1145",
// 说话人,源自配置文件
"spk": "ikaros",
// 音调
"tran": 1.0,
// 输出音频格式
"wav_format": "wav"
},
// edge-tts相关配置
"edge-tts": {
// edge-tts选定的说话人(cmd执行:edge-tts -l 可以查看所有支持的说话人)
"voice": "zh-CN-XiaoyiNeural"
// 语速增益 默认是 +0%,可以增减,注意 + - %符合别搞没了,不然会影响语音合成
"rate": "+0%",
// 音量增益 默认是 +0%,可以增减,注意 + - %符合别搞没了,不然会影响语音合成
"volume": "+0%",
// 语速
"speed": 1
},
// elevenlabs相关配置
"elevenlabs": {
// elevenlabs密钥,可以不填,默认也有一定额度的免费使用权限,具体多少不知道
"api_key": "",
// 选择的说话人名
"voice": "Domi",
// 选择的模型
"model": "eleven_monolingual_v1"
},
// genshinvoice.top相关配置
"genshinvoice_top": {
// 说话人
"speaker": "神里绫华",
// 输出音频格式 不建议修改
"format": "wav",
// 可用于控制整体语速。默认为1.2
"length": "1.25",
// 控制感情变化程度,默认为0.2
"noise": "0.2",
// 控制音节发音长度变化程度,默认为0.9
"noisew": "0.9"
},
// chatterbot相关配置
"chatterbot": {
// 机器人名
"name": "bot",
// bot数据库路径
"db_path": "db.sqlite3"
},
// chatgpt相关配置
"chatgpt": {
"model": "gpt-3.5-turbo",
// 控制生成文本的随机性。较高的温度值会使生成的文本更随机和多样化,而较低的温度值会使生成的文本更加确定和一致。
"temperature": 0.9,
"max_tokens": 2048,
"top_p": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"preset": "请扮演一个AI虚拟主播。不要回答任何敏感问题!不要强调你是主播,只需要回答问题!"
},
// text-generation-webui相关配置
"text_generation_webui": {
// 服务监听的IP和端口
"api_ip_port": "http://127.0.0.1:5000",
"max_new_tokens": 250,
// 有 'chat', 'chat-instruct', 'instruct'
"mode": "chat",
// 角色
"character": "Example",
// 聊天指导模板
"instruction_template": "Vicuna-v1.1",
// 你的名字
"your_name": "你"
},
// 是否启用本地问答库匹配机制,优先级最高,如果匹配则直接合成问答库内的内容/返回本地音频,如果不匹配则按照正常流程继续。
"local_qa": {
// 文本匹配模式
"text": {
// 是否启用
"enable": true,
// 文本问答库文件路径,数据为一问一答形式(换行分隔)
"file_path": "data/本地问答库.txt"
},
// 音频匹配模式
"audio": {
// 是否启用
"enable": true,
// 文本问答库音频文件路径,匹配的关键词就是音频文件名,为模糊最优匹配
"file_path": "out/本地问答音频/"
}
},
// 点歌模式设置
"choose_song": {
// 是否启用 true启用 false关闭
"enable": true,
// 点歌触发命令(完全匹配才行)
"start_cmd": "点歌 ",
// 停止点歌命令(完全匹配才行)
"stop_cmd": "取消点歌",
// 歌曲音频路径(默认为本项目的song文件夹)
"song_path": "song",
// 匹配失败返回的音频文案 注意 {content} 这个是用于替换用户发送的歌名的,请务必不要乱删!影响使用!
"match_fail_copy": "抱歉,我还没学会唱{content}"
},
// stable diffusion相关配置
"sd": {
// 是否启用
"enable": false,
// 触发的关键词(弹幕头部触发)
"trigger": "画画:",
// 服务运行的IP地址
"ip": "127.0.0.1",
// 服务运行的端口
"port": 7860,
// 负面文本提示,用于指定与生成图像相矛盾或相反的内容
"negative_prompt": "ufsw, longbody, lowres, bad anatomy, bad hands, missing fingers, pubic hair,extra digit, fewer digits, cropped, worst quality, low quality",
// 随机种子,用于控制生成过程的随机性。可以设置一个整数值,以获得可重复的结果。
"seed": -1,
// 样式列表,用于指定生成图像的风格。可以包含多个风格,例如 ["anime", "portrait"]。
"styles": [],
// 提示词相关性,无分类器指导信息影响尺度(Classifier Free Guidance Scale) -图像应在多大程度上服从提示词-较低的值会产生更有创意的结果。
"cfg_scale": 7,
// 生成图像的步数,用于控制生成的精确程度。
"steps": 30,
// 是否启用高分辨率生成。默认为 False。
"enable_hr": false,
// 高分辨率缩放因子,用于指定生成图像的高分辨率缩放级别。
"hr_scale": 2,
// 高分辨率生成的第二次传递步数。
"hr_second_pass_steps": 20,
// 生成图像的水平尺寸。
"hr_resize_x": 512,
// 生成图像的垂直尺寸。
"hr_resize_y": 512,
// 去噪强度,用于控制生成图像中的噪点。
"denoising_strength": 0.4
},
// 文案相关配置(待更新)
"copywriting": {
// 文案文件存储路径,不建议更改。
"file_path": "data/copywriting/",
// 文案文件存储路径2,不建议更改。
"file_path2": "data/copywriting2/",
// 文案音频文件存储路径,不建议更改。
"audio_path": "out/copywriting/",
// 文案音频文件存储路径2,不建议更改。
"audio_path2": "out/copywriting2/",
// 播放音频文件列表
"play_list": [
"测试文案2.wav",
"测试文案3.wav",
"吐槽.wav"
],
// 播放音频文件列表2
"play_list": [
"test.wav"
],
// 文案音频播放之间的间隔时间。就是前一个文案播放完成后,到后一个文案开始播放之间的间隔时间。
"audio_interval": 5,
// 文案音频切换到弹幕音频的切换间隔时间(反之一样)。就是在播放文案时,有弹幕触发并合成完毕,此时会暂停文案播放,然后等待这个间隔时间后,再播放弹幕回复音频。
"switching_interval": 5,
// 文案随机播放,就是不根据播放音频文件列表的顺序播放,而是随机打乱顺序进行播放。
"random_play": true
},
"header": {
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42"
},
// 聊天模式相关配置
"talk": {
// 你的名称
"username": "主人",
// 使用的语音识别类型 baidu / google
"type": "google",
// 录音触发按键(长按此按键进行录音)
"trigger_key": "1",
// 音量阈值,指的是触发录音的起始音量值,请根据自己的麦克风进行微调到最佳
"volume_threshold": 800,
// 沉默阈值,指的是触发停止路径的最低音量值,请根据自己的麦克风进行微调到最佳
"silence_threshold": 15,
// 百度语音识别 申请:https://console.bce.baidu.com/ai/#/ai/speech/overview/index
"baidu": {
// 百度云 语音识别应用的 AppID
"app_id": "",
// 百度云 语音识别应用的 API Key
"api_key": "",
// 百度云 语音识别应用的 Secret Key
"secret_key": ""
},
// 谷歌语音识别
"google": {
// 录音后识别转换成的目标语言(就是你说的语言)
"tgt_lang": "zh-CN"
}
},
// 字幕相关配置
"captions": {
// 是否启用字幕记录
"enable": true,
// 字幕输出路径
"file_path": "log/字幕.txt"
}
}
ChatGPT 代理
- 例如 API2D
"openai": {
// 代理地址,需要和官方接口一致的才行。例如:api2d
"api": "https://oa.api2d.net/v1",
// 代理站提供的密钥
"api_key": [
"fkxxxxxxxxxxx"
]
}
- one-api
官方仓库:one-api
或者纯代理的镜像站
-
合作伙伴 智来星球 提供
-
源自互联网
-
如何配置呢?
GUI中openai api地址配置为:
http://openai-pag.wangzhishi.net/v1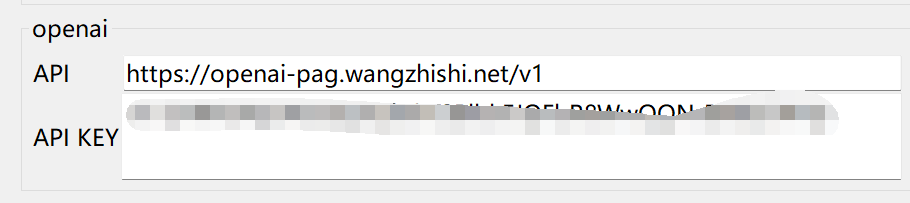
chat_with_file 模式说明
一. 模式简介
用户上传的“人物设定”文件(如PDF、TXT等格式),允许用户自定义并配置角色的背景信息和设定。
1.用户提出查询时,系统首先在本地文档库中执行相似性搜索,以寻找与查询最相关的文档。
2.接着,系统将这些相关文档连同用户的查询一起作为输入,提交给语言模型。该模型据此生成答案。
3.如果系统在本地文档库中未能找到与用户查询相关的文档,或者语言模型无法基于当前输入生成有意义的答案,系统可能无法回应用户的查询。
二. 模式配置
为了使用chat_with_file功能,您需要将chat_type设置为chat_with_file。在启用此功能之前,请确保您已经配置好了如openai、claude等模型的访问token。
chat_with_file支持以下几种模式,您可以通过设置chat_mode来选择相应的模式:
-
claude:选择claude作为聊天模型。请确保您已经完成了相关配置。 -
local_vector_embedding_model:使用本地向量数据库模式。在此模式下,系统会利用本地向量数据库来存储和检索数据。 -
openai_vector_search:仅利用向量数据库进行查询,而不调用GPT模型,这样可以节省token,并且能够进行快速的本地数据搜索。目前,此模式采用OpenAIEmbedding进行数据的向量化处理,因此需要您提前配置好OpenAI的相关设置。 -
openai_gpt:在向量数据库中检索到相关信息后,将其作为输入传递给GPT模型进行更深层次的处理。
我们推荐使用claude模式,因为它可以免费使用,并且不会消耗openai的token。
注意
-
所有模型都应该采用
HuggingFace模型,暂未适配其他模型 -
本地模型存储目录是
data/text2vec_models,将自己的模型存储到该位置,在config.json配置中填写该模型的文件夹名字即可 -
如果需要其他模型,可以从
HuggingFace中下载下来,存放到对应位置即可 -
也可以直接输入
HuggingFace的模型名字,如 GanymedeNil/text2vec-large-chinese ,项目会自动从远程仓库下载。-
请确保能够连接上
HuggingFace(可能需要科学上网) -
远程仓库下载的模型,一般存储在系统cache中。win端一般是
C:\Users\用户\.cache\torch\sentence_transformers。也可以将其移动到项目模型存储目录下使用
-
-
openai_vector_search和openai_gpt读取本地数据的内容默认以换行为分隔符,所以可能导致大标题数据丢失问题,需要注意你的数据内容在编辑时不要将核心的内容放在标题部分单独一行,导致丢失 核心数据,尽量将标题和正文写在一行,在真的需要分割的部分进行换行。
使用
Note
运行webui,python webui.py,配置平台配置、直播间号等,具体参考视频教程。
实战教程:【AI主播-实战篇】AI前台/客服/看板娘,现实中对话AI,提供聊天/知识问答服务,实际全配置演示,手把手带你应用
各版本都需要做的前期准备操作。
Chatterbot
Chatterbot 相关安装&使用
运行环境
Python 3.6+
安装依赖
在命令行中安装所需的Python库,您可以使用以下命令:
pip install spacy ChatterBot
如果遇到ChatterBot安装错误,您可以尝试安装更新版本的ChatterBot。首先,访问ChatterBot的更新版本仓库:
从该GitHub仓库下载更新版本的ChatterBot后,您可以在下载的文件夹内运行以下命令来安装:
python setup.py install
如果您在安装过程中遇到速度慢的问题,可以考虑单独安装依赖项。例如,如果您需要安装SQLAlchemy,可以使用以下命令:
pip install SQLAlchemy==1.3.24
如何训练自己的AI?
- 打开
data/db.txt,写入你想要训练的内容,格式如下
问
答
问
答
- 将文件重命名为
data/db.txt - 在命令行中运行以下命令启动程序:
python train.py
- 训练完的模型名叫
db.sqlite3,直接双击main.py即可使用
常见问题
- 提示缺少
en-core-web-sm,打开终端输入
python -m spacy download en_core_web_sm
- 报错:no module named ‘spacy’解决办法
pip install spacy
哔哩哔哩
注意:如果使用方案2,需要手动克隆官方项目仓库的 blivedm 到site-packages
抖音
先安装第三方弹幕捕获软件,参考 补充-抖音
抖音版 旧版
不稳定
运行前请重新生成一下protobuf文件,因为机器系统不一样同时protobuf版本也不一样所以不能拿来直接用~
protoc -I . --python_out=. dy.proto
快手
方案1:
请在安装完依赖后,安装火狐浏览器内核。参考命令:playwright install firefox
如果你是整合包,项目路径打开cmd,然后使用 Miniconda3\python.exe Miniconda3\Scripts\playwright.exe install firefox 进行安装。
使用新版本时需要注意,请使用小号登录,然后在每次用完之后,把 cookie 文件夹下的 123.json 文件删掉!!!用过一次后 cookie 就异常了,所以需要删了重新登录!!!
方案2:
配合油猴脚本:https://greasyfork.org/zh-CN/scripts/490966,在浏览器直播间页面监听DOM变动,WS返回数据。
浏览器安装油猴插件后,再安装上面的脚本,打开需要监听的直播间后,就会自动监听弹幕,连接WS服务,然后把AI Vtuber运行起来,进行对接。
方案0:
运行前请重新生成一下 protobuf 文件,因为机器系统不一样同时 protobuf 版本也不一样所以不能拿来直接用~
protoc -I . --python_out=. ks.proto
微信视频号
Note
安装监听程序(不保证安全性,自行斟酌) wxlivespy,设置监听地址为http://127.0.0.1:8082/wxlive,开播!开始监听,扫描登录直播的微信号。webui修改平台为微信视频号,运行即可。
拼多多
配合油猴脚本:https://greasyfork.org/zh-CN/scripts/490966,在浏览器直播间页面监听DOM变动,WS返回数据。
浏览器安装油猴插件后,再安装上面的脚本,打开需要监听的直播间后,就会自动监听弹幕,连接WS服务,然后把AI Vtuber运行起来,进行对接。
斗鱼
打开您的浏览器,找到您需要监听的直播间,然后按F12打开开发者工具,点击Console(控制台),复制 douyu_ws_client.js 脚本中的内容,粘贴到控制台,回车运行,启动监听服务
douyu_ws_client.js
let socket = null;
function connectWebSocket() {
// 创建 WebSocket 连接,适配服务端
socket = new WebSocket("ws://127.0.0.1:5000");
// 当连接建立时触发
socket.addEventListener("open", event => {
console.log("ws连接打开");
// 向服务器发送一条消息
// socket.send("ws连接成功");
});
// 当收到消息时触发
socket.addEventListener("message", event => {
console.log("收到服务器数据:", event.data);
});
// 当连接关闭时触发
socket.addEventListener("close", event => {
console.log("WS连接关闭");
// 重连
setTimeout(() => {
connectWebSocket();
}, 1000); // 延迟 1 秒后重连
});
}
// 初始连接
connectWebSocket();
// 选择需要观察变化的节点
const targetNode = document.querySelector('.Barrage-list');
// 创建观察器实例
const observer = new MutationObserver(mutations => {
mutations.forEach(mutation => {
// 这里处理新增的DOM元素
if (mutation.type === 'childList') {
mutation.addedNodes.forEach(node => {
// 判断是否是新增的弹幕消息
if (node.classList.contains('Barrage-listItem')) {
// 新增的动态DOM元素处理
// console.log('Added node:', node);
const spans = node.getElementsByTagName('span');
let username = "";
let content = "";
for (let span of spans) {
//console.log(span);
if (span.classList.contains('Barrage-nickName')) {
const targetSpan = span;
// 获取用户名
let tmp = targetSpan.textContent.trim().slice(0, -1);
if (tmp != "") username = targetSpan.textContent.trim().slice(0, -1);
} else if (span.classList.contains('Barrage-content')) {
const targetSpan = span;
// 获取弹幕内容
content = targetSpan.textContent.trim();
}
}
console.log(username + ":" + content);
// 获取到弹幕数据
if (username != "" && content != "") {
const data = {
type: "comment",
username: username,
content: content
};
console.log(data);
socket.send(JSON.stringify(data));
}
}
})
}
});
});
// 配置观察选项
const config = {
childList: true,
subtree: true
};
// 开始观察
observer.observe(targetNode, config);